Internal Developer Portals (IDPs) have increasingly found their way to the center of engineering operations. As the new engineering system of record, IDPs make it possible to align and enforce standards while unlocking safe developer self-service. Of course, oft-cited benefits like removing friction and improving consistency might feel intangible or even duplicative to other tools in your stack. So how should engineering leaders think about evaluating IDPs?
In this blog we’ll help you wade through high level value drivers to get to the meat of what IDPs can do, for whom, and towards what quantifiable end. Let’s dig in.
What are IDPs?
First, a quick overview to get you up to speed: As summarized in our recent guide, the CTO Pocket Guide to Internal Developer Portals, Internal Developer Portals (IDPs) are the new connective tissue of engineering organizations—finally linking all engineering data, tools, teams, and standards to ensure continuous alignment to goals.
As such, IDPs serve three critical functions:
Single source of truth. An IDP integrates with, connects across, and allows for unified querying of all of the engineering teams’ data sources, including IT, infrastructure, source control, service definitions, APIs, workforce management, and in the case of IDPs that offer custom data and a plugin framework—data from any internally developed tools.
Quality standards enforcer. An IDP supports reporting on and enforcement of standards of excellence—be they short term initiatives like software migrations or long-term programs like resource optimization and service maturity. With an IDP, standards are centralized, monitoring is continuous, and action is obvious.
Engineering accelerator. With always-up-to-date information about their ecosystem, engineers can onboard faster, reduce incident response time, and increase velocity. IDPs that enable true self-service can also automate or obviate parts of production like templating new software, requesting permissions, or waiting on approvals.
What engineering metrics can an IDP help improve?
In discussing which metrics IDPs “move,” we’ll speak to specific outcomes under three broader use cases:
System of Record Metrics - Ensuring onboarding developers can quickly find details about software their team owns reduces time to meaningful commits. Similarly, reducing time to find critical details like ownership and dependencies speeds incident response.
Standards Alignment Metrics - Ensuring alignment to standards of excellence reduces overall organizational risk—security risk from excessive vulnerabilities, operational risk from duplicative work, churn risk from unreliable products, and attrition risk from developers frustrated with excessive escalations.
Developer Productivity Metrics - Reducing context switching and rote work improves developer satisfaction while also improving an organization’s ability to quickly innovate, iterate, and bring new products to market faster.
Mean Time to Respond or Resolve (MTTR)
A system’s crash rate is a reliable signal of stability issues that affect user satisfaction, while a system’s availability or uptime are a way of measuring how often a system is operational and ready for use. When incidents do occur, the incident rate—for example, how many are opened in a week—and the mean time required to resolve the incidents are quick gauges of software quality and the responding team’s productivity.
By centralizing all engineering data—including that coming from security tools, APM tools, on-call information, and your organization’s identify provider— teams can immediately find who owns what, what happened last, and what needs to happen next. Critical inputs are constantly flowing into your Internal Developer Portal catalogs, while active scorecards can ensure the presence of critical assets like run books and relevant documentation.
Incident frequency or severity
IDPs can help reduce increase frequency or severity by enabling teams to "stack the deck" with security and operational best practices that alert owners when software begins to drift. Add rules that look for things like connection to the latest vulnerability scanners, use of up to date packages, no more than 1 unresolved P0 vulnerability, or no more than 5 open service tickets.
By keeping software up to date with best practice on a continuous basis, IDPs reduce context-switching that slows devs, and ultimately your go-to-market efforts.
Change failure rate
Engineering teams with distributed architectures are facing a record number of incidents that take longer to resolve than ever before. How much time is your team spending on fixing problems instead of developing new projects? Even if you’re checking all the boxes for testing and monitoring when preparing software for production, how are you ensuring continuous alignment to best practice? Things like presence of documentation, run books, up to date packages, and a manageable number of open tickets and vulnerabilities?
IDPs help reduce change failure rate by enabling teams to set continuous standards of excellence designed to reduce time spent resolving avoidable issues.
New software onboarding
Getting new software into production is a time consuming process that can take multiple cycles of context gathering, code writing, testing, fixing, approvals, fixing, and more approvals. These processes often lack rigor or consistency across the broader organization, and tend to gravitate to the path of least resistance.
But "abbreviating" requirements for the sake of speed almost always takes a toll in other areas when software security and reliability isn't what you'd expect. IDPs optimize the process of production readiness to reduce time to ship new software, while also improving the health of it to preserve uptime and reliability. Use scaffolding to obviate the need to write boilerplate code for common scenarios, and add actions to reduce friction in onboarding new software. Together, developers gain weeks of time back per use case.
Pull requests raised and time to review
These metrics are used to track how many pull requests are opened, and the time it takes for them to be reviewed. If many pull requests are being opened but not reviewed in a timely manner, it indicates reviewers are overwhelmed or there is insufficient review bandwidth. This can serve as a proxy for velocity since it’s a metric for development throughput.
All Internal Developer Portals house the components for these metrics, but those with built-in Engineering Intelligence solutions can aggregate and surface this information in a more structured format, enabling teams to benchmark status, and even set goals by team or individual with connected scorecards.
Deployment frequency and PR size
Shipping smaller chunks of code can reduce risk, speed troubleshooting, and improve time to market. It’s a best practice that many software engineers have taught themselves to observe by default, but can quickly tank productivity if not observed in perpetuity.
Internal Developer Portals with Engineering Intelligence capabilities enable you to set standards of code quality, size, and even PR response times in order to improve overall deployment frequency and operational efficiency—setting goals for your team to track against, and ensuring managers are alerted when drift occurs, so they can work to unblock teams facing challenges that prevent achievement of best practice.
Deployment velocity
Several factors influence a developer’s ability to ship code quickly—time required to gather context, number of competing priorities, percentage of time spent resolving issues, and of course tools, mentorship, and experience.
Internal Developer Portals positively impact deployment velocity by centralizing the tools and tasks needed to be optimally productive. IDPs eliminate rote work once required to connect context across multiple tools, prioritize tasks by deadline and criticality, or even write boilerplate code for commonly constructed services. IDPs also reduce time spent waiting on approvals for common tasks in onboarding, deploying services, or provisioning infrastructure.
Release schedule adherence
Release Schedule Adherence measures the degree to which actual releases align with planned release schedules, and is calculated by comparing planned and actual release dates. This number is often a reflection of how many unplanned interruptions affect your developers' work plan, like unexpected escalations, incidents, or slow PR review time. Poor release adherence can affect go-to-market speed and competitive win rates for external products, and engineering efficiency for internal platforms and products.
Internal Developer Portals improve release schedule adherence by ensuring all deployment plans are centralized, and automatically updated and reported upon to reduce ambiguity about how to get started or what comes next. Task prioritization also helps reduce ambiguity about what needs attention when, while scorecards reduce overall likelihood of incident from avoidable issues cause by things like excessive unresolved vulnerabilities or out of date packages.
New engineer onboarding time
It can take months for new engineers to feel up to speed enough to make meaningful contributions to code. Part of this process is locating disparate information about tools, systems, and processes, but a good chunk of time is also spent just gaining access to systems.
If your IDP offers chained workflows, onboarding becomes a one-click process that frees up both SRE/DevOps teams and individual devs seeking access to new tools.
Time to migrate or integrate
Engineering teams are always making changes—to code, infrastructure, tools, standards, and more. But it’s not easy to get everyone aligned on time. Initiatives as complex as managing an M&A, migrating to the cloud, or adopting Kubernetes take multiple years, while even tasks as simple as package upgrades can take several months—requiring exemption requests in the case of vendor-issued end-of-life notices. This can accrue to opportunity cost of foregone savings from new technology or frameworks, and real costs of supporting outdated software.
IDPs let teams develop migration plans that only alert relevant owners with information about what to do, by when, and actively monitor software for conditions matching those defined in rules about the change. Managers can then track progress, and rest assured that updates, alerts, and deadlines are automatically enforced.
Developer experience / morale
Engineering morale tracks how satisfied team members are with their work and work environment. Morale tends to drop when tech debt increases and code quality decreases, so understanding the attitude of the team can indicate a lot about the health of the codebase.
Software catalogs, scorecards, task prioritization, and developer self-service offered by IDPs can have an outsized impact on developer experience by reducing toil across the entire continuum of work they own, from context gathering to troubleshooting and deployment.
Can IDPs track engineering metrics?
You may use several tools to track software health metrics like uptime and reliability, and several others for efficiency metrics like change failure rate, or PR open to close time. But if multiple teams are manually managing that process, it’s likely your data may lack consistency of definition and freshness.
Since IDPs make it possible to standardize data across all tools, they’re a natural platform for increasing fidelity of the data you use to make critical decisions about software and teams.
When choosing an IDP, it might be useful to prioritize those with built-in engineering intelligence metrics that logically connect to software health metrics, making it easy for leaders to take action that will positively impact software, as well as engineering productivity and happiness.
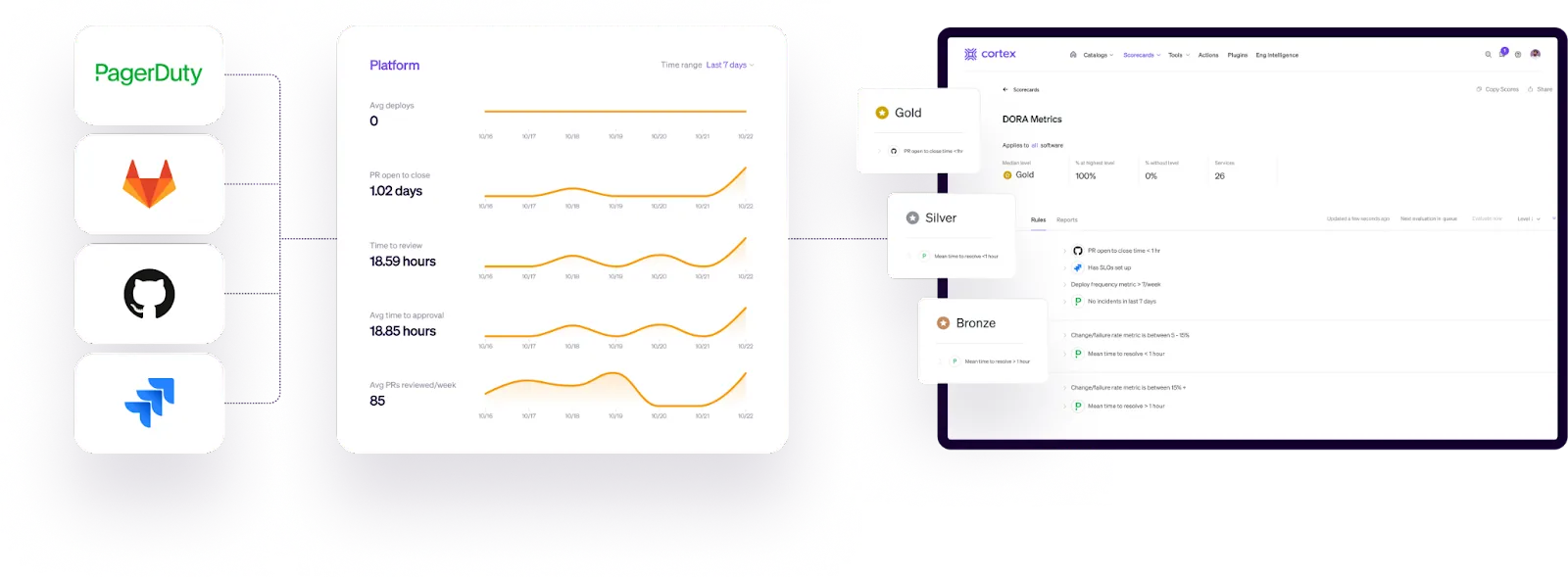
Cortex’s Internal Developer Portal
Cortex pioneered the three requirements for Internal Developer Portals:
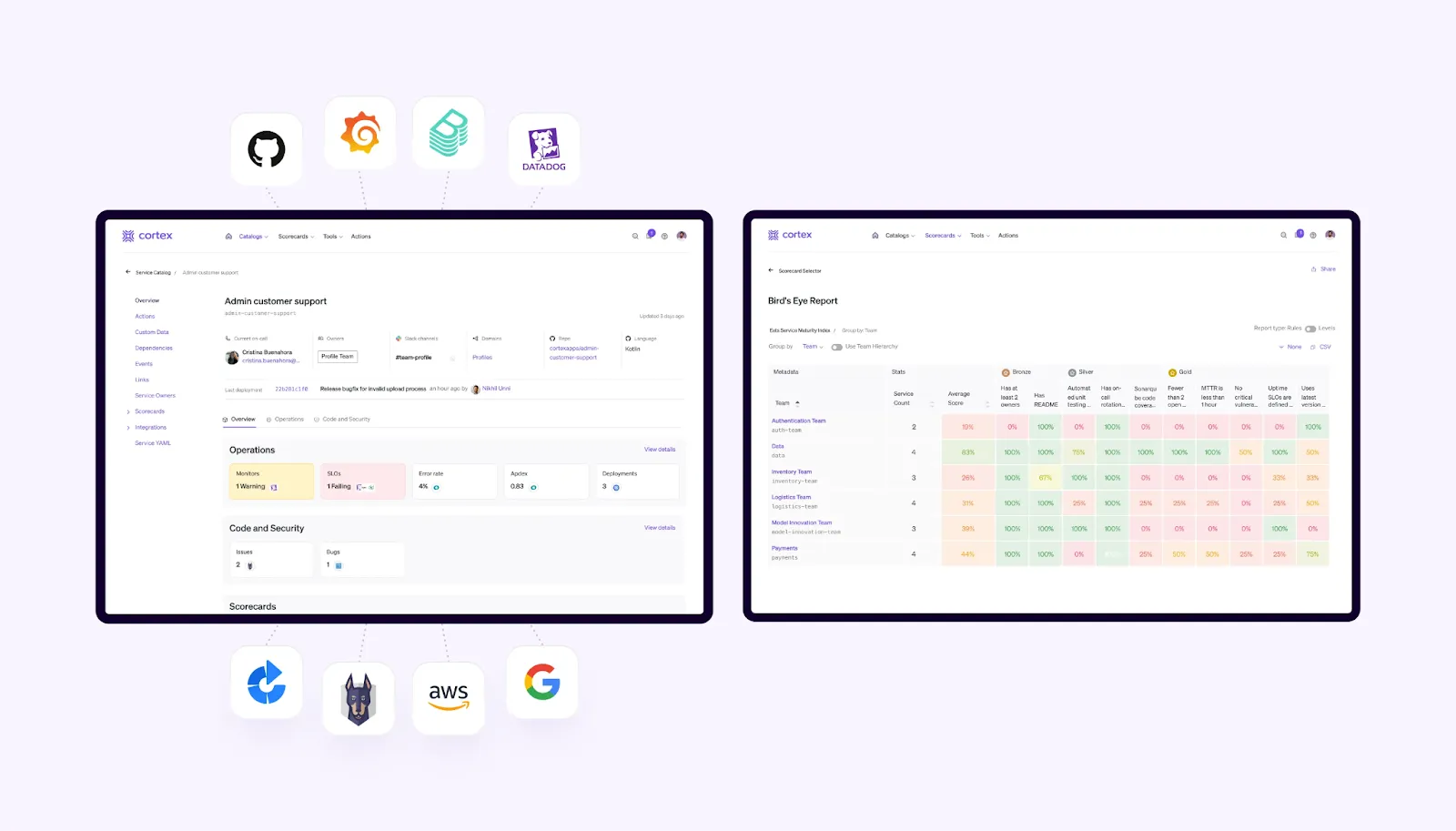
Centralize data and standards across all tools
Cortex was designed to facilitate maximum flexibility without excessive overhead. Fully custom catalogs, 50+ out of the box integrations, the ability to bring in custom data, and a rich plugin architecture enables teams to build new data experiences that best fit developer workflows.
Anything that details how software is built, by whom, when, and how, can be captured by catalogs segmented by software type like services, resources, APIs, infrastructure, etc. Any standard that governs how code is written, tested, secured, reviewed, or deployed can be unified, and even re-segmented by team, type, domain, or exemption status, to ensure all components are managed in context.
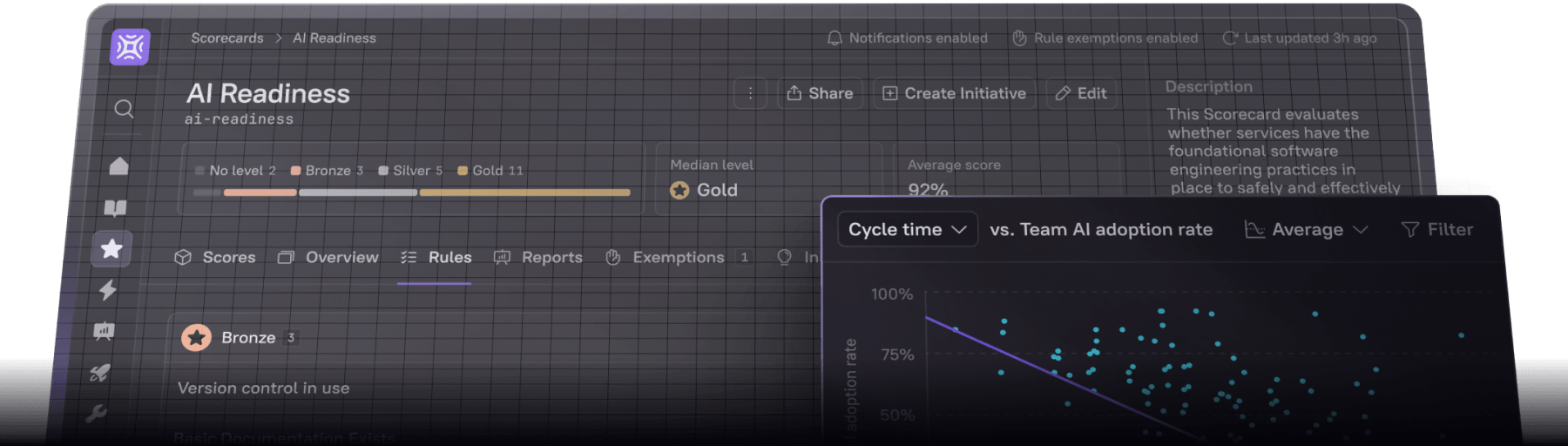
Apply always-on standards for continuous alignment
Code repos, project management tools, and wikis are all indisputably useful tools for engineering teams. But none have a live view of the rest of your software ecosystem, which means none can tell you when software falls out of alignment with critical requirements for security, compliance, or efficiency.
Because Cortex is a one-stop-shop for all your data and documentation, it can also serve as a means of continuously monitoring alignment to all software standards you define in a scorecard. So if code is updated, ownership changes, new tools are adopted, or old packages hit end-of-life, Cortex makes it easy to see what needs attention.
Cortex is the only IDP that provides the level of data model flexibility to define any rule, for any data, targeting any audience. This means users can create Scorecards with rule types like:
Binary: Check for connection to a vulnerability scanner or use of the most up to date package
Target: Require at least 70% code coverage or two reviewers
Threshold: Allow no more than one p0 vulnerability, or five open Jira tickets per service
In order to ensure scorecards aren’t just passive assessment systems, Cortex also enables teams to drive meaningful action by:
Defining deadlines—so certain measures are actioned before a set date and time
Pushing alerts—via Slack, Teams, or email to ensure devs know what’s needed, when
Uploading exemption lists—to target only the folks that need to take action
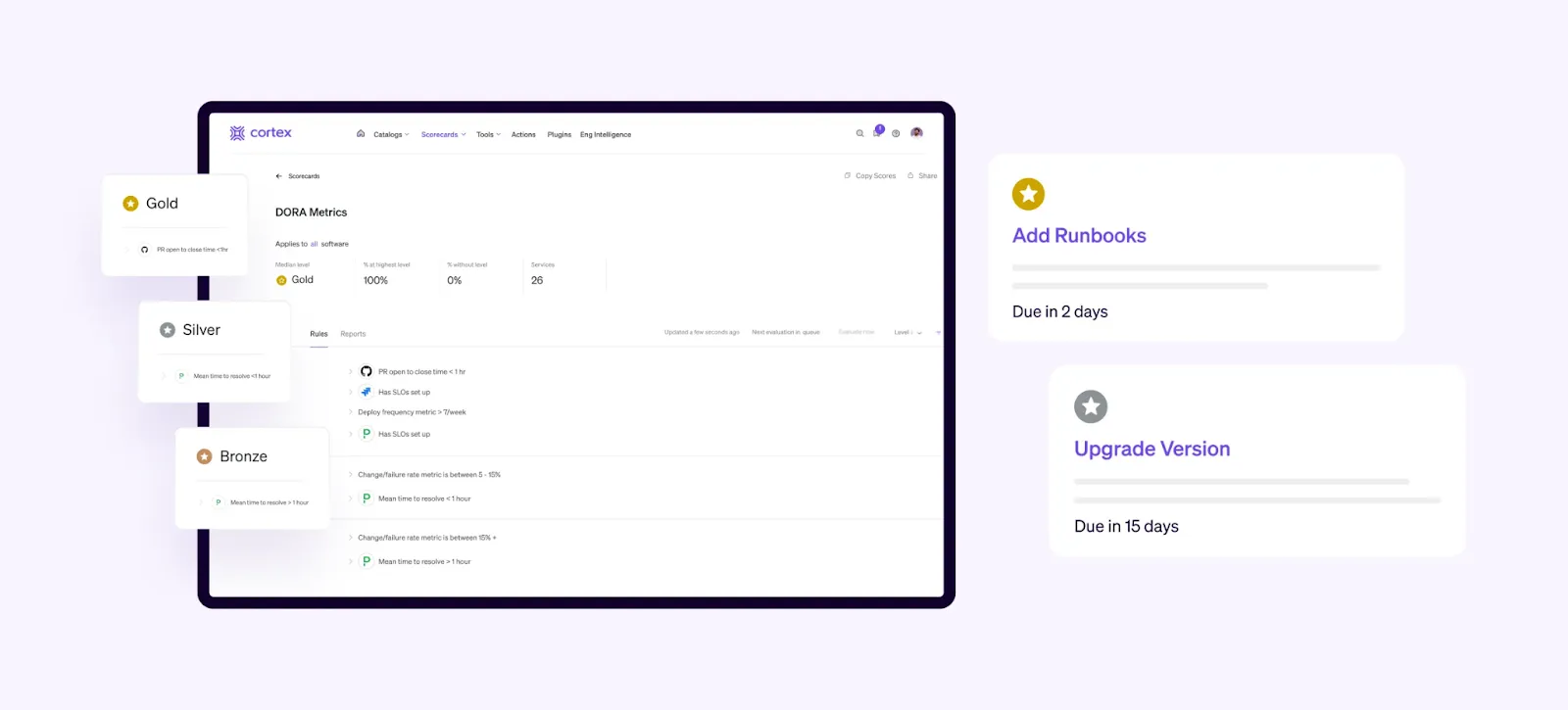
Provide approved templates to ship quality code quickly
Enabling self-service is a top priority engineering leaders that care about both developer productivity, and happiness. But self-service also contributes to higher quality software, and therefore should be part of any robust production readiness process. Cortex enables teams to create pre-approved templates with health checks built in, so developers can reduce time spent looking for standards and context-switching across applications.
Don’t just build production readiness standards into templates with boilerplate code, but initiate any workflow from within the platform using a customizable HTTP request, data transformation, user input request, Slack message, and manual approval. Now developers can do things like:
Onboard a new developer
Shore up incident content quickly
Provision new resources
Make an API call to AWS
Deploy a service
Provision a resource
Assign a temporary access key
Create a JIRA ticket, or r any other action that would help the developer complete a task, or in this case, their production readiness checklist
Self-serve templates and workflows are also especially useful for onboarding new developers that would normally need time to ramp on your chosen production readiness protocol. By centralizing the tools and templates needed to align with standards, time to impact can be drastically reduced.
Track key engineering metrics
By spotting bottlenecks and investigating problems’ root causes, Cortex Eng Intelligence makes it possible to uncover bigger trends and drive meaningful change that elevate quality and productivity.
Use metrics as lagging indicators to improve how engineering teams work together, and communicate goals via Cortex’s developer homepage to make it easy for developers to know what’s next, and why it matters.
For more information on how Cortex can help you align, track, and improve critical engineering metrics, hop into the product, or schedule a custom demo today!