In all of the recent calls I’ve had with Engineering leaders interested in Cortex, I’ve been asked, “How can you help with incident response?” We know there’s no shortage of IR tooling in market, so I’ve come to realize the question is more about how we close the gaps between them, rather than whether we can replace what they have in house today.
The TLDR is that having all your engineering data in one place—particularly, 1) Service ownership information, and 2) Feeds from all your response tooling makes it incredibly easy to find owners, inspect events, and raise or dismiss alerts, without context switching. Internal Developer Portals make this a reality.
In this blog I’ll talk through exactly what that before and after might look like for your organization, using a simple but very common scenario.
Incident Response before Cortex: An Endless Cycle of Who? What? Where?
Meet our hero, Jordan. Jordan is a developer that’s just trying to focus on a new project, when yet another incident pulls them away from coding.
Step 1: Who owns what?
Jordan is focused on developing a new feature when an alert comes in from their monitoring tool—something’s down. They quickly abandon their work and start investigating. The first hurdle? They don’t know who owns the service that’s causing the issue. Ownership information isn’t centralized, so Jordan spends time pinging various team members in Slack to figure out who’s responsible for the failing service.
Step 2: Where are the runbooks?
After spending valuable time identifying the right team, Jordan starts digging into the logs to figure out what’s wrong. They quickly realize that the runbooks—the documentation that should guide them through troubleshooting—are out of date or incomplete. Now, they’re forced to piece together a response plan, taking more time than necessary just to figure out what should be done.
Step 3: What’s the history?
With no centralized view of recent incidents or past events, Jordan wastes even more time trying to track down if this issue has happened before. Maybe it has, but with no unified system to look through, it’s impossible to know if this is a recurring problem or a one-time failure.
Step 4: Reset for tomorrow
By the time Jordan resolves the issue, hours have been lost. Worse, they know this scenario will repeat itself tomorrow. Every incident seems to be a scavenger hunt—digging for information, finding the right person to help, and constantly firefighting instead of actually building.
Total time wasted: Hours, if not days, spent tracking down information, chasing teams, and searching through disconnected systems.
Incident Response After Cortex
A few months later, Cortex is implemented, bringing real-time visibility, and centralized ownership to the company. The impact on Jordan’s incident response process is immediate.
Step 1: Always Up-to-Date Ownership
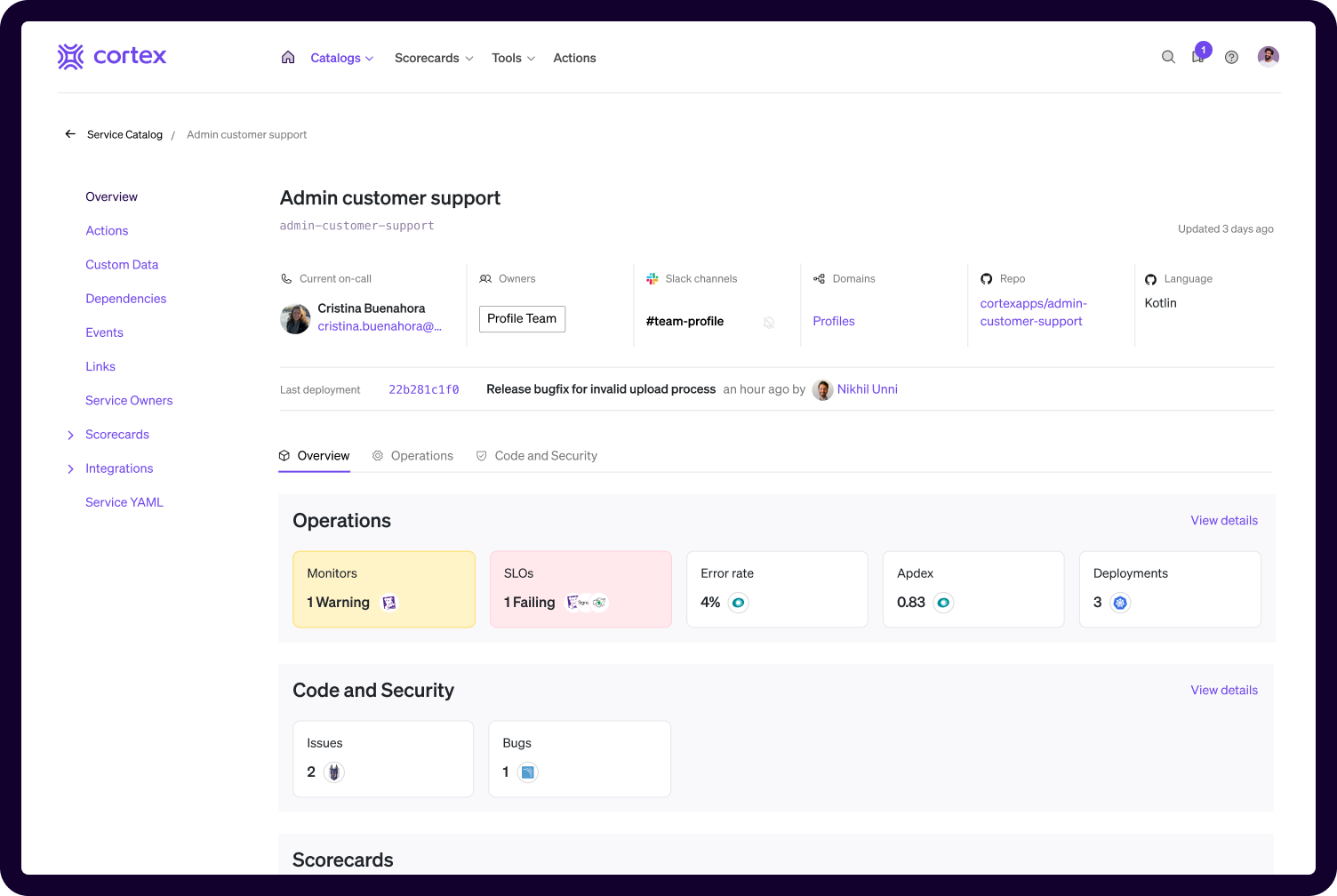
With Cortex, Jordan no longer has to spend time tracking down service owners. Thanks to integrations with their identity providers, Cortex Catalogs provide a centralized view of ownership for every service. As soon as an incident occurs, Jordan can see exactly who owns the service, what team is responsible, and how to contact them—in one platform.
Features in use:
Cortex service catalog for real-time visibility into service ownership
Step 2: Reliable Runbooks
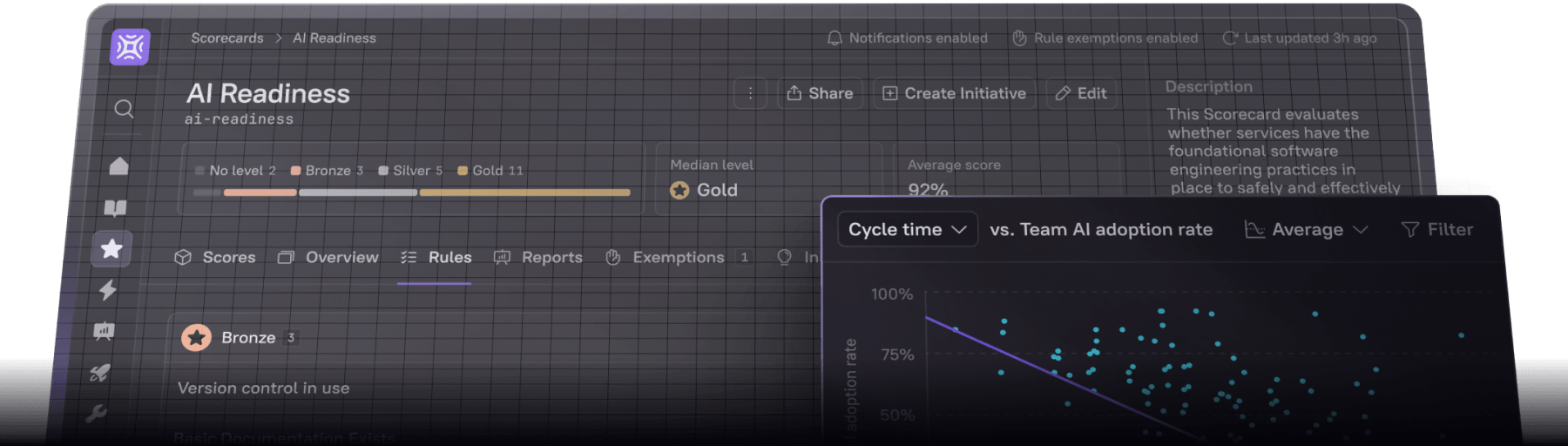
No more guessing when it comes to troubleshooting. Cortex ensures that all services have up-to-date runbooks linked directly in the service catalog. Jordan can now follow a clear, predefined set of instructions, avoiding the need to troubleshoot from scratch. Cortex’s Scorecards automatically track the availability and accuracy of runbooks, ensuring they are always ready and reliable.
Features in use:
Cortex scorecards to ensure that runbooks are complete, accurate, and up to date.
 Bird's Eye Report of a Service Maturity Scorecard in Cortex
Bird's Eye Report of a Service Maturity Scorecard in Cortex
Step 3: Real-Time Access to Recent Events
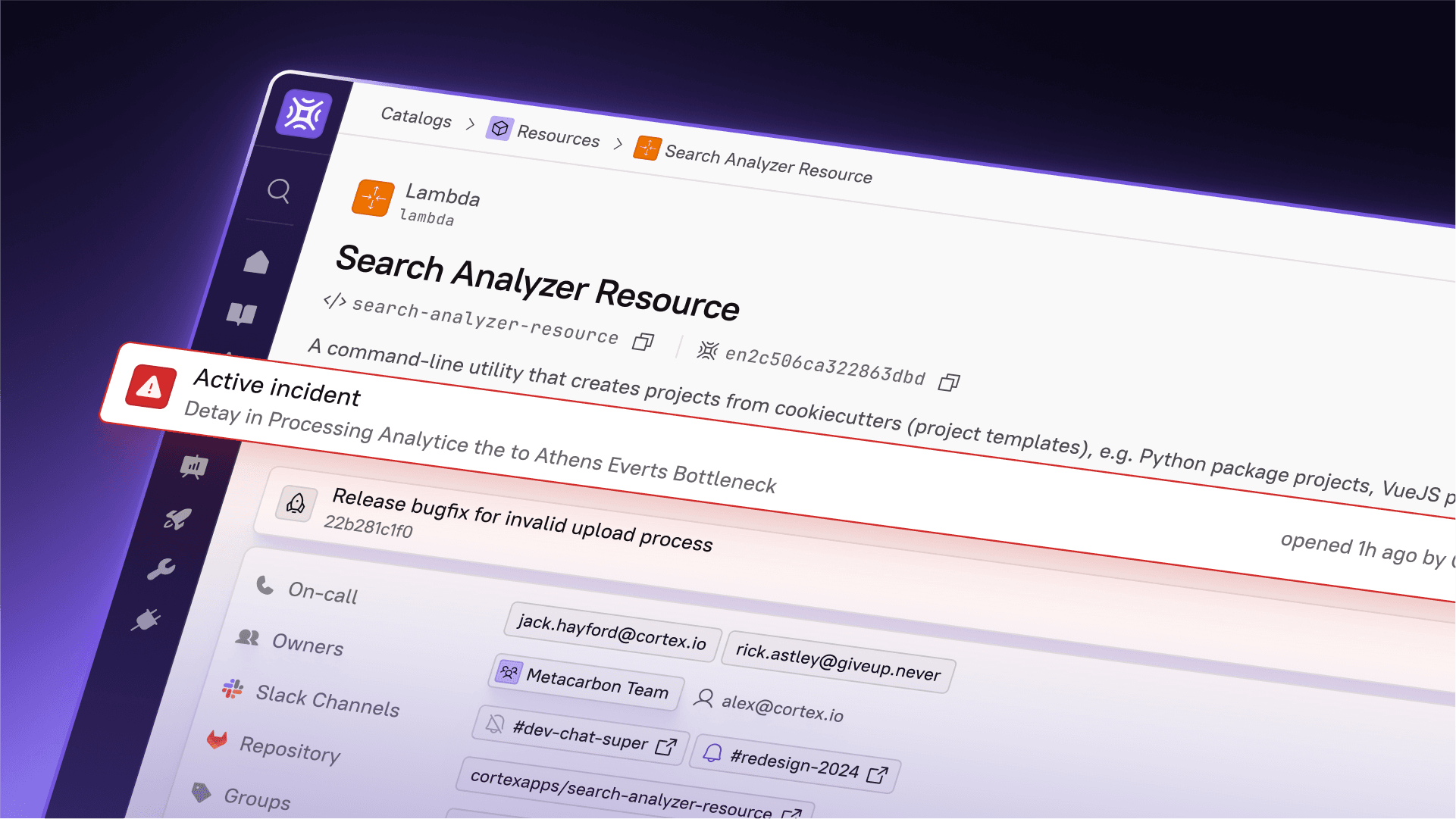
When an incident occurs, Jordan no longer has to sift through multiple tools to figure out if the issue has happened before. Cortex provides real-time access to recent incidents and events linked to the affected service. With just a few clicks, Jordan can see if this issue is part of a recurring pattern, whether similar incidents were resolved, and what actions were taken.
Features in use:
Cortex entity detail pages and dashboards for tracking recent incidents and event histories in real-time.
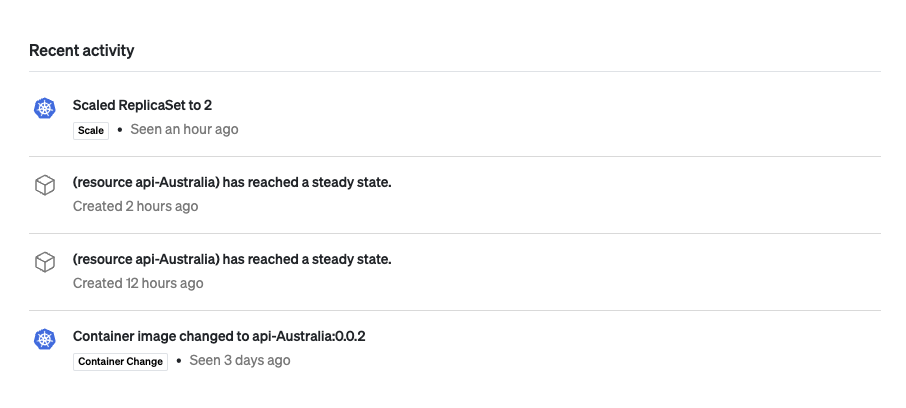 Recent activity log in a service entity detail page within Cortex
Recent activity log in a service entity detail page within Cortex
Step 4: Preventing Future Incidents
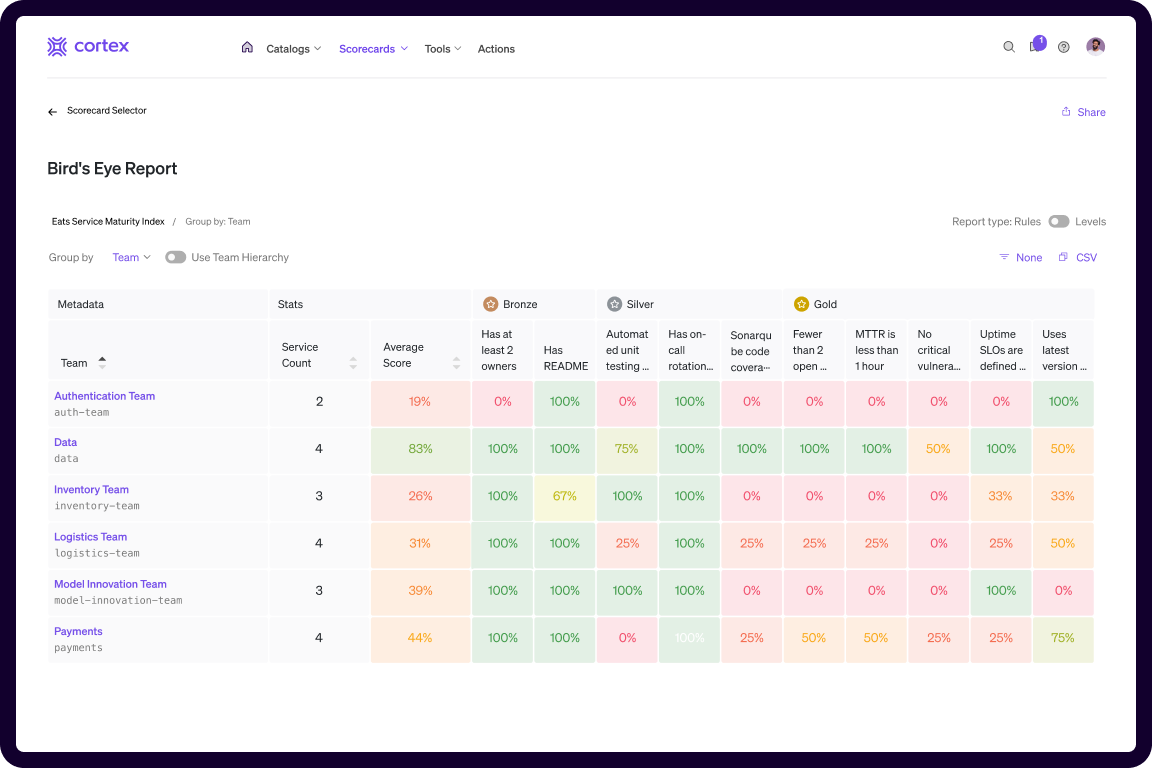
Beyond fixing the current issue, Cortex helps prevent future incidents by continuously monitoring the status of services against best practices your organization defines. With automated scorecards that track everything from number of unresolved incidents and vulnerabilities to code coverage and SLO attainment, Cortex helps identify risks before they turn into real problems. Jordan can see which services are missing critical components like runbooks, health checks, or security compliance, and proactively address them.
Features in use:
Cortex scorecards for tracking service health, compliance, and readiness
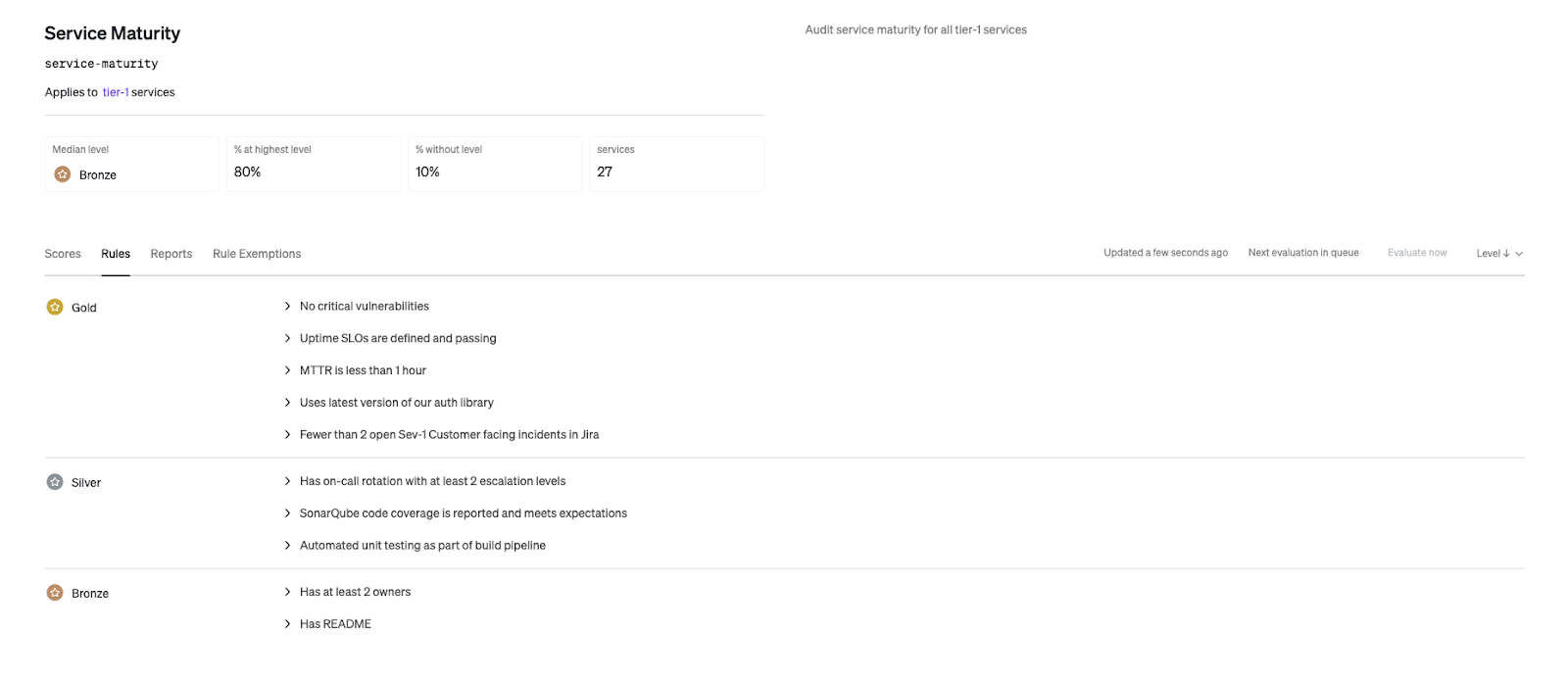 Service Maturity Scorecard in Cortex
Service Maturity Scorecard in Cortex
The Results: Time Saved and Less Frustration
In this scenario, Cortex helped Jordan refocus on building new value by spending less time on incidents, and less time responding to the ones that do occur.
Incident Manager benefit
Time spent identifying service ownership and troubleshooting dropped from hours to minutes. The service catalog and real-time incident tracking eliminated the need for manual investigation and coordination with other teams.
Platform or SRE benefit
Cortex’s Scorecards and notifications allow developers to focus on long-term stability instead of responding to the same incidents repeatedly. With real-time insights into service health and owner accountability, Platform Engineers and SREs can shift from reactive to proactive work.
Developer benefit
Instead of being bombarded with scattered notifications, service owners receive clear, actionable notifications that tell them exactly what needs attention. This reduces delays and helps ensure faster resolution of incidents.
In total, Cortex cut hours off the incident resolution process and empowered Jordan’s team to focus on their real work—building and delivering features.
Better Incident Response with Cortex
Cortex transformed Jordan’s company’s incident response process by centralizing ownership, automating runbook availability, and providing real-time insights into service health and recent incidents. With Cortex’s Scorecards ensuring that critical documentation is always up-to-date and easily accessible, Jordan no longer wastes time hunting down information or tracking down the right people. Issues are resolved faster, and teams can focus on preventing future incidents, rather than constantly fighting fires, as depicted in the below image:
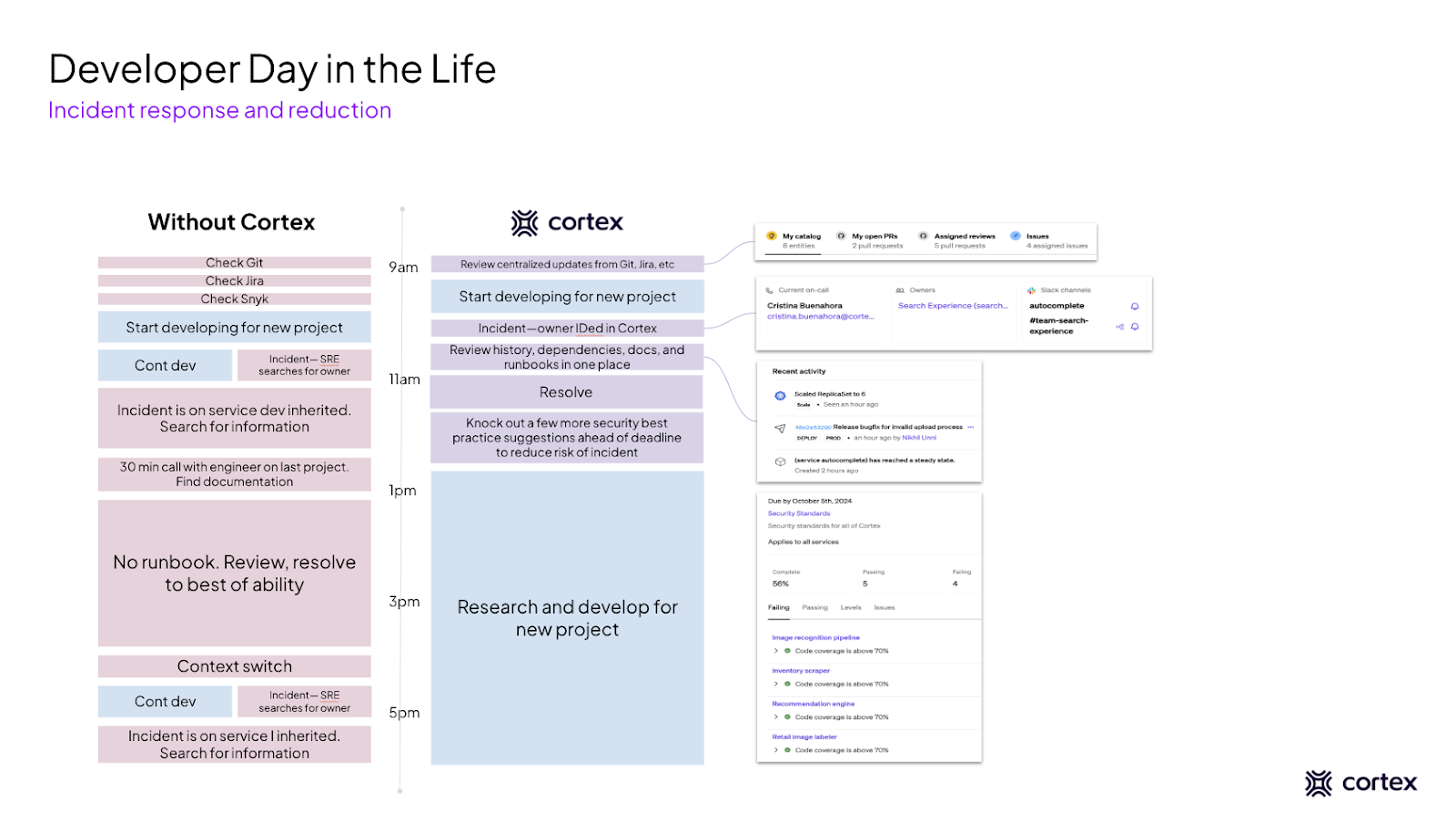 Bottom line, if your company’s incident response process feels more like an unorganized scramble than a well-oiled machine, Cortex can help bring control to the chaos. By centralizing service ownership, automating critical documentation, and providing real-time visibility into owners and dependencies, Cortex not only helps resolve issues faster but also empowers your team to prevent them from happening in the first place. For teams looking to improve their incident response, Take the tour, or set up a custom demo today.
Bottom line, if your company’s incident response process feels more like an unorganized scramble than a well-oiled machine, Cortex can help bring control to the chaos. By centralizing service ownership, automating critical documentation, and providing real-time visibility into owners and dependencies, Cortex not only helps resolve issues faster but also empowers your team to prevent them from happening in the first place. For teams looking to improve their incident response, Take the tour, or set up a custom demo today.