Site reliability engineering is a critical part of software development, so it makes sense that a wealth of tools have emerged over the past two decades to help SREs maximize the reliability and stability of your application.
SREs are responsible for adopting tools that can minimize manual work and improve the reliability of applications for end users. This might include monitoring tools, on-call management tools, incident management tools, configuration and automation tools, microservice catalog tools — with all of these options, it can be difficult to know which ones are worth considering.
In this guide, we’ll take a look at some of the main types of SRE tools and some of the specific standouts in each category.
Monitoring tools
Monitoring tools generate valuable metrics and insights about an application, enabling SREs to set benchmarks, debug issues, and track improvement over time. There are tools for almost anything related to your application that you want to measure, so the first step is figuring out what is is you’re trying to measure.
Monitoring, by textbook definition, is the process of collecting, analyzing, and using information to track a program’s progress toward reaching its objectives and to guide management decisions. Monitoring focuses on watching specific metrics.
Application performance monitors model the response times perceived by your end users, and compare metrics against performance benchmarks to detect latency and outages.
Network monitoring tools evaluate the incoming and outgoing traffic routed through your network. These tools can help with load balancing, debugging client/server issues, and stopping network attacks before they occur.
Infrastructure monitoring assesses consumption rates and SLOs for components of your applications to help with resource management. For example, this tool may monitor the CPU load for your Kubernetes clusters. Regardless of the type of monitoring tool that will work best for your team, there are a few important features to consider:
Alerts: Your monitor should be able to generate alerts when metrics approach and/or exceed thresholds set by your SRE team.
Automated incident response: Ideally, your tools will automatically try to address any detected issues where possible, reducing overhead for your engineering team.
Logging: A monitor should create detailed logs that contain all the information you need to debug an issue. Ideally, the monitor will have configurable highlighting to make the information easier to traverse.
Visualizations/dashboards: Monitors have all kinds of graphics and charts to help you interpret data at a glance and share insights with stakeholders. Depending on your use case, you may look for tools that can support specific data round-ups and visual representations.
Supported integrations: Perhaps most importantly, your monitor should work seamlessly with your application’s services and resources.
Monitoring and observability tools
There are a number of monitoring tools that have earned a good reputation from SRE teams. Note that there are both open-source and subscription-based options available.
Grafana helps SREs generate dashboards and visualizations by integrating with other monitoring tools. Grafana can be used with a range of data stores, including Google Cloud Monitoring, PostgreSQL, Splunk, Prometheus, and GitHub.
Prometheus is a popular monitoring tool with an active community and broad range of features. Prometheus uses an HTTP pull model to record metrics in real time, and offers real-time alerting and flexible queries.
Datadog offers end-to-end visibility for cloud-scale applications, and is widely used by organizations to gain insight into apps. As a major player, Datadog has a lot of advantages, including 350+ integrations. For large organizations, Datadog can also provide role-based access control and auditing.
Splunk is generalized tool best for managing big data and deriving actionable insights, boasting full-stack visibility at any scale. Splunk can query large-scale data and generate reports to XYZ. As a SIEM, Splunk also collects high volumes of network data in real time, so you can gain insight into your app’s security, too.
On-call management tools
SREs and engineers are often required to be on-call during working and non-working hours in case there’s an issue that threatens your system’s health. This can be a stressful position to be in, especially if the right tools aren’t in place to make sure the resolution process is a smooth one. Not only can an on-call tool ensure incidents are addressed quickly, but it can also minimize the burden of being on call.
While most on-call tools also help your team manage the incident itself, we’ll be covering incident management in the next section. Here are some on-call rotation specific features to help you prioritize your assessment:
Scheduling: A good on-call management tool should help you distribute shifts equally and fairly across your team. Ideally, this tool also offers a degree of flexibility, so team members can trade on-call rotations at the last minute when needed.
Calendar sharing: Especially in an era of microservices, an incident often impacts multiple components, which means several on-call engineers will likely need to be involved in the resolution. People need to know who else is on-call to work together quickly. For this reason, it’s important that your on-call tool has an easy way for people across your organization to see the calendar.
Alerts: Alerts are absolutely essential, so your on-call tool should integrate with your monitoring tools to deliver alerts. An on-call tool must also deliver a payload with enough context so the on-call engineer can fully address the issue. Ideally, an on-call manager will give you rules-based configurations for alert routing..
On-call management tools
PagerDuty offers automated incident management and facilitates on-call scheduling. Plus, PagerDuty has more than 700 integrations with services like JIRA, ServiceNow, AWS, and Salesforce.
Splunk OnCall, formerly known as VictorOps, is an on-call management tool made by engineers for engineers. Splunk has an edge when it comes to contextual support, offering a targeted approach for resolution every step of the way.
Opsgenie, Atlassian’s on-call management tool, offers flexibility for different teams and approaches, as well as dynamic reports that help you identify the key areas for improvement.
Incident management tools
Incidents are inevitable, and whoever is on call will need powerful tools to swiftly address the issue and get the system back up and running. To make sure your response is a durable one, an incident management tool should enable your team to establish clear escalation paths, well-defined response procedures, and a blameless post-mortem culture. SREs can find tools to codify these practices and help your team communicate better and resolve incidents faster.
Issue triage: Your tool should help you configure issue types and severity levels to make it easy to know how to prioritize issues and when to escalate.
Escalation pathways: Whether issues are manually or automatically escalated, you should be able to quickly get the right people involved and easily share all of the context they need to understand the issue.
Runbooks: Depending on the nature of the issue, your tool should present a runbook with the defined steps the on-call engineers need to follow. Your tool should also be able to automatically execute workflows if certain conditions are met.
Real-time communication: An incident manager should integrate with the apps your team uses to communicate, like Slack or Jira, to share information, so engineers are free to focus on the issue at hand. It should also create a historical document of the incident response that your team can refer to later on.
Data-driven issue analysis: Ideally, your tool will give you all the data you need to understand what happened and identify steps for avoiding the same issue down the road.
Incident management tools
All of the on-call management tools we mentioned above feature some form of incident management. If you’re looking for a dedicated tool specifically for incident management, there are a few standouts:
Blameless is an incident management tool focused dedicated to automation. Blameless offers automated data collection and reporting, saving your team hours of manual work trying to identify the root cause of an issue.
ServiceNow offers users a platform for managing workflows — ServiceNow lets you track IT workflows, customer workflows, and employee workflows, so you can gain insight into every aspect of your application.
Configuration and automation tools
A core part of the SRE’s value is in automation — an SRE team should minimize the mindless manual work involved in software development. SREs often use automated configurations not only to decrease manual work, but also to make sure the same steps are always followed when provisioning, managing, and destroying resources. There are a few features that are particularly helpful in this respect.
Infrastructure as code: Infrastructure specifications should live in a file that can be run to recreate your configuration in the event of an outage. Most automation tools have their own language for defining a desired configuration.
Execution planning: Your tool should preview the effects of your changes before you run an automation, so you can make sure there is no unexpected behavior.
Automated workflows: A configuration tool should allow you to enforce steps that are always followed when performing a task, and let you run these workflows automatically.
Container orchestration: If you use a container orchestration service like Kubernetes for deployment, your configuration tool should be compatible with that service as well.
Configuration/automation tools
Terraform is a popular open-source infrastructure-as-code tool that allows SREs to automate infra for provisioning, compliance, and management of any cloud, data center, and service. Terraform can be used to manage Kubernetes, to integrate with existing workflows, and enforce policy as code, among a number of other use cases.
Ansible boasts simplicity when it comes to automation management. This command-line IT automation software is also focused on security and reliability, which is why it comes with few moving parts.
Developer portals
One of the best ways to manage incidents is to avoid them in the first place, which is why SREs should also have a tool that helps them enforce high-level standards and best practices. A developer portal acts as single source of truth for SREs, featuring service and resource catalogs. A developer portal can help minimize siloed knowledge at your organization, which becomes especially important when teams work remotely and manage dozens of microservices.
A developer portal should have a few key features that helps your SRE teams drive adherence to service quality standards across teams:
Production readiness checklists: Production readiness checklists are vital not only for SREs, but for developers and engineers on every team. This predefined checklist makes sure that a service is ready for deployment, and may include things like confirming the existence of a load balancer and end-to-end testing.
Transparent ownership: The service and resource catalogs in a developer portal should clearly identify the owner of every component, so it’s easy to find the responsible person or team when an issue arises. (Ideally, you’ll also be able to find owners’ contact information listed in the catalogs.)
Integrates with your existing tools: All the best practices you’re trying to enforce should be visible within a single source of truth, so your developer portal should be able to integrate with all the monitoring, on-call, incident management, and configuration tools that your SRE team uses. For example, your APM logs and on-call rotation schedule should appear alongside services within a catalog, so SREs can find all the information in one place.
Automatic updates: When your configurations or policies change, you shouldn’t need to make manual edits in your developer portal — it should automatically update to reflect all changes in your environment.
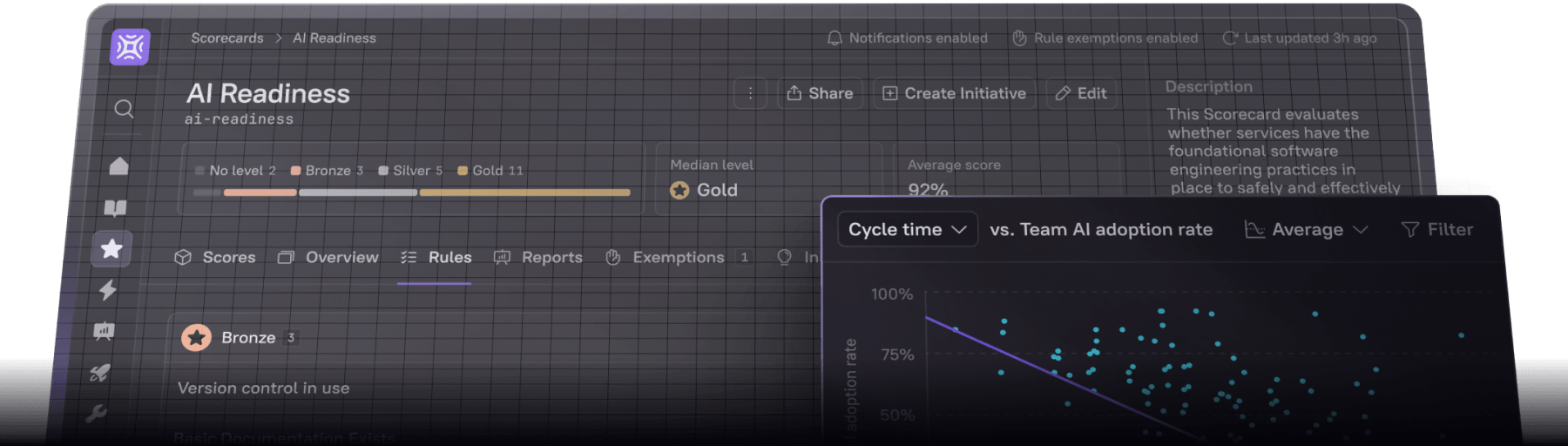
Make Cortex your go-to SRE tool
The most common governance tool we’ve seen is, unfortunately, a giant spreadsheet — or, worse, several giant spreadsheets! This is wholly antithetical to the SRE philosophy.
We created Cortex to serve as your single source of truth, so SREs have one core tool they can use to bridge development and ops teams, monitor service performance, drive adherence to standards, and improve service quality. Cortex helps organizations foster a culture of accountability through gamified Scorecards and helps teams drive improvement by providing visibility on every level.
With the right tools, your SRE team will be able to improve your application’s reliability and performance, while freeing up time for developers to evolve the product and add innovative features. To see how Cortex can take your SRE team to the next level, book a free demo today!